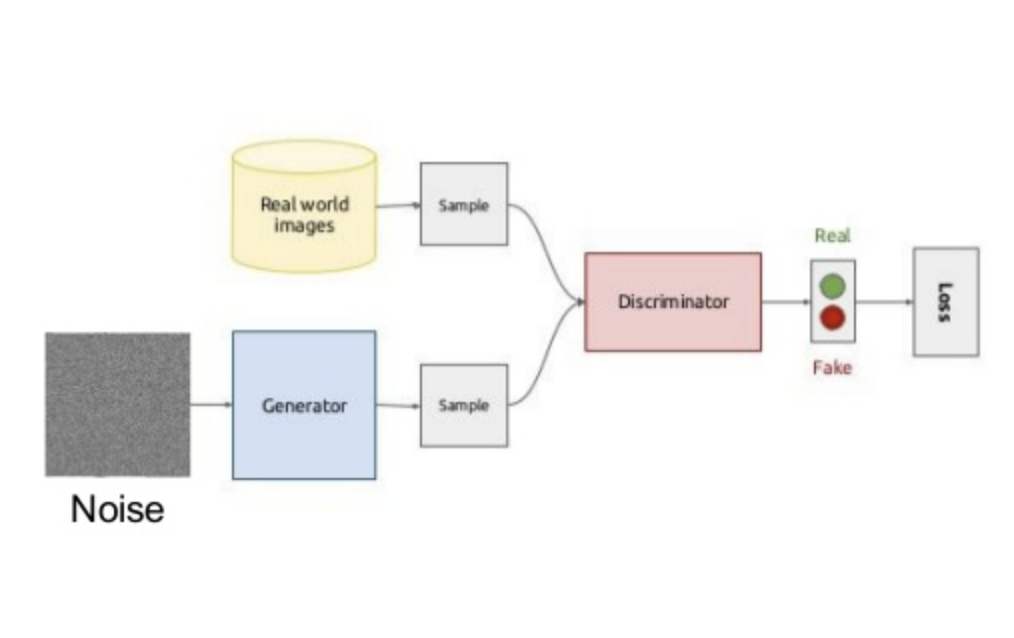
Generative_Adversarial_Networks
生成对抗网络(Generative Adversarial Networks)
\begin{align}
\end{align}1. GAN生成对抗网络的原理及实现模型结构及优化
目标函数:
V\left(D,G\right)=\mathbb{E}_{\mathbf{x}\sim p_{data}\left(\mathbf{x}\right)}\left[\log D\left(\mathbf{x}\right)\right]+\mathbb{E}_{\mathbf{z}\sim p_\mathbf{z}\left(\mathbf{z}\right)}\left[\log\left(1-D
2020-05-05
Deep Learning
GAN
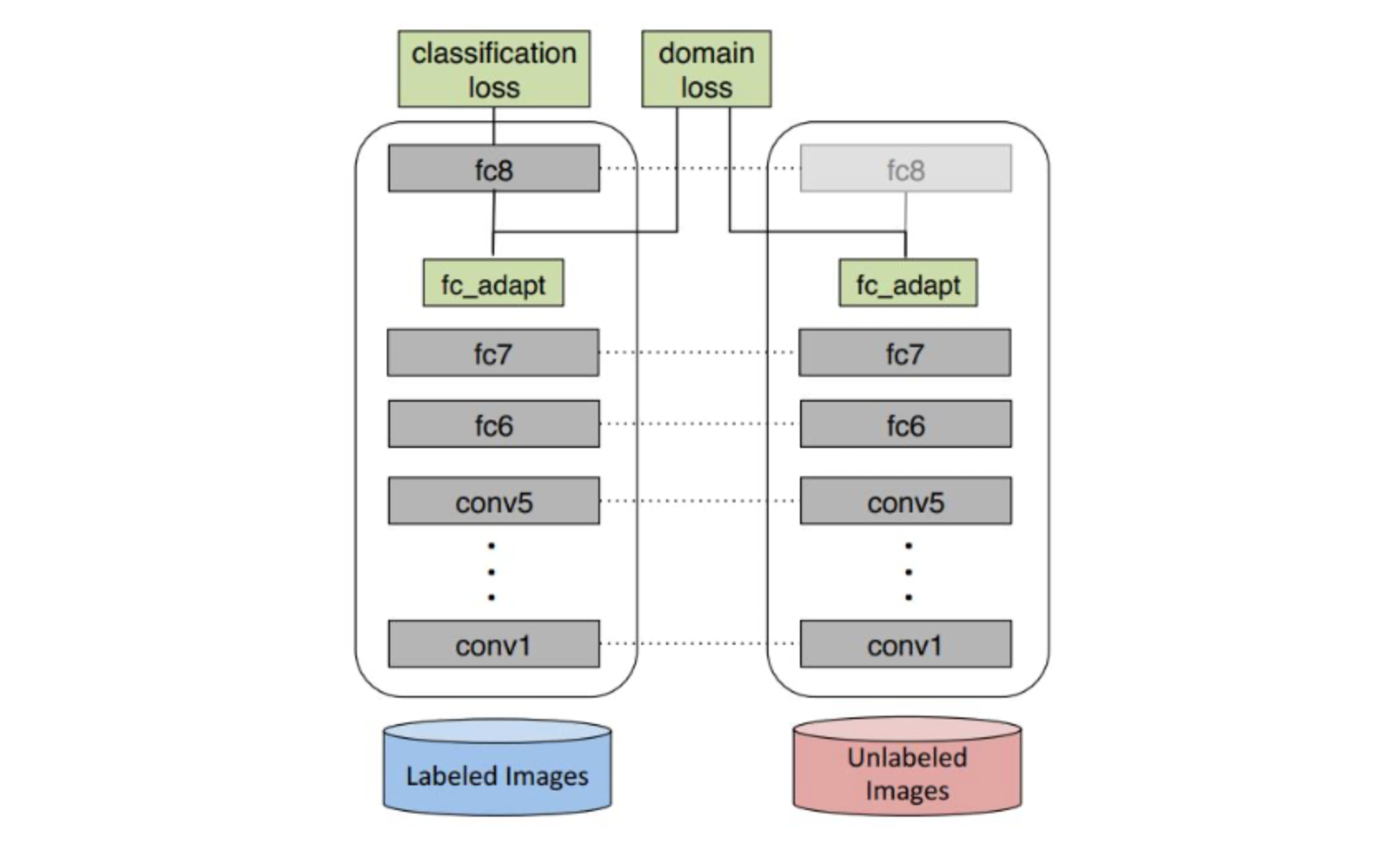
Transfer_Learning
迁移学习(Transfer Learning)
\begin{align}
\end{align}1 迁移学习的形式化定义领域$\mathcal{D}$:数据及数据的概率分布源领域$\mathcal{D}_s=\{\left(\mathbf{x}_i,y_i\right)|P_s\left(\mathbf{x}_i\right)\}_{i=1}^n$目标领域$\mathcal{D}_t=\{\mathbf{x}_j|P_t\left(\mathbf{x}_j\right)\}_{j=n+1}^{n+m}$
迁移学习(Transfer Learning):给定有标记源领域$\mathcal{D}
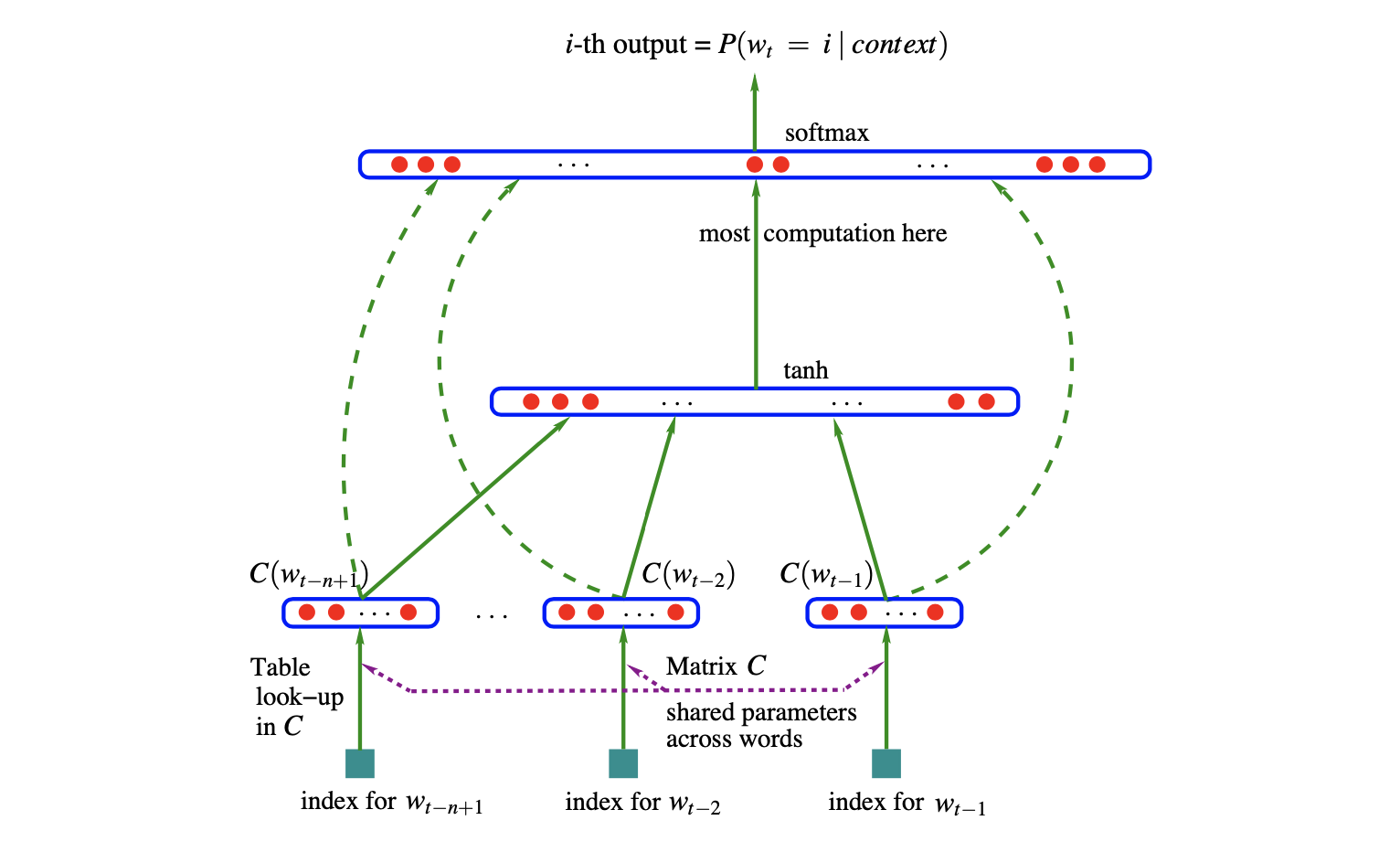
Nerual_Probabilistic_Language_Model
A Neural Probabilistic Language Model
\begin{align}
\end{align}1 统计语言模型与n-gram模型统计语言模型可描述为给定前序词序列后,下一单词出现的条件概率的乘积:
\hat P\left(w_1^T\right)=\prod_{t=1}^T\hat P\left(w_t|w_1^{t-1}\right)其中,$w_t$是第$t$个单词,$w_i^j=\left(w_i,w_{i+1},\dots,w_{j-1},w_j\right)$是从第$i$个单词到第$j$个单词的子序列。
n-gram模型可描述为给定前$n-1$个单词后,

Feedforward_Nerual_Network
前馈神经网络(Feedforward Neural Network,FNN)
\begin{align}
\end{align}1 前馈神经网络结构及前向传播训练数据集\begin{align} \\& T = \left\{ \left( \mathbf{x}_{1}, y_{1} \right), \left( \mathbf{x}_{2}, y_{2} \right), \cdots, \left(\mathbf{x}_i,y_i\right),\cdots,\left( \mathbf{x}_{N}, y_{N} \right) \right\} \end{align}其中,$
2020-05-05
Deep Learning
nerual network
Recurrent_Nerual_Network
循环神经网络(Recurrent Neural Network,RNN)
\begin{align}
\end{align}1 循环神经网络结构数据集
\big\{\left(\mathbf{x}_t,\mathbf{y}_t\right)\big\}_{t=1}^T其中,第$t$时刻输入数据$\mathbf{x}_t=\left(x_t^{\left(1\right)},x_t^{\left(2\right)},\dots,x_t^{\left(n\right)}\right)^{\top}\in\mathbb{R}^n,$第$t$时刻输出数据$\mathbf{y}_t=\left(y_
2020-05-05
Deep Learning
nerual network
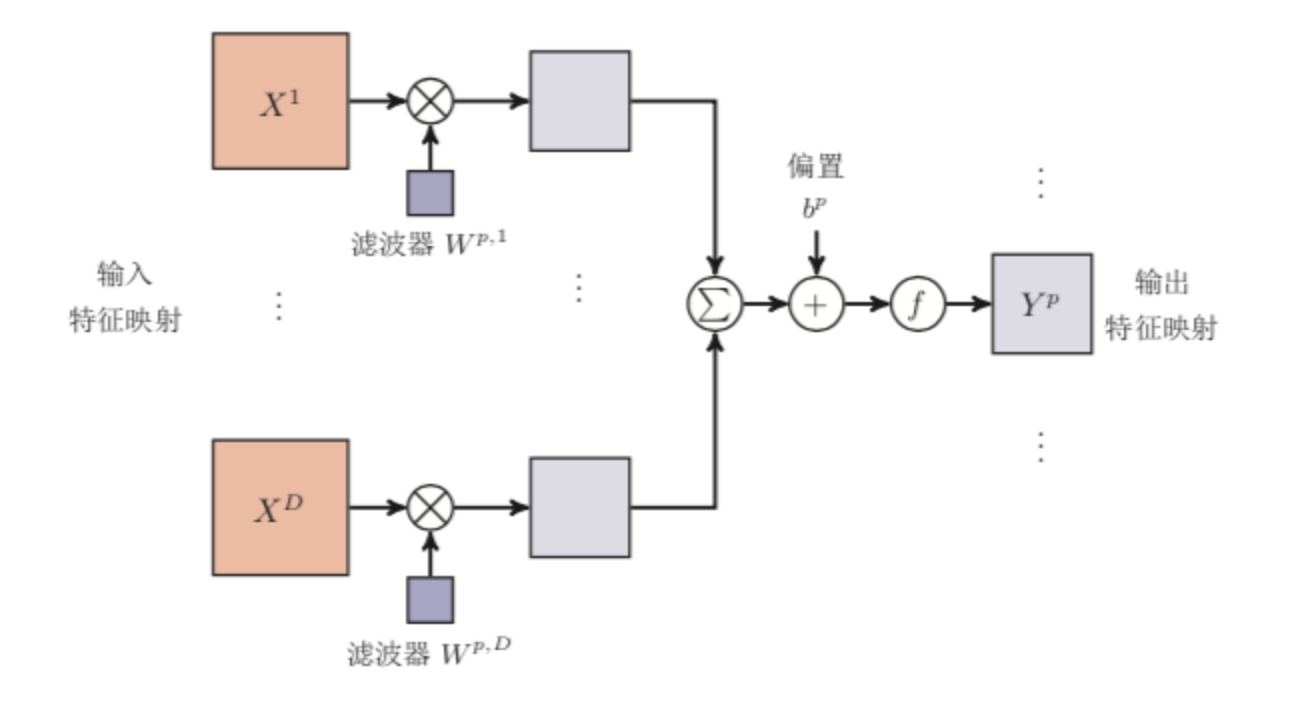
Convolutional_Nerual_Network
卷积神经网络(Convolutional Neural Network,CNN)
\begin{align}
\end{align}卷积神经网络一般由卷积层、汇聚层和全连接层交叉堆叠而成的前馈神经网络,使用误差反向传播算法进行训练。
1 卷积基础一维卷积:信号发生器每个时刻$t$产生一个信号$x_t$,生成信号序列$\left(x_1,x_2,\cdots,x_t,\cdots\right)$。其信息衰减率为$w_k$,即在$k-1$个时间步长后信息为原来的$w_k$倍,将$\left(w_1,w_2,\cdots,w_k,\cdots\right)$称为滤波器或卷积核。
设滤波器序列为$\l
2020-05-05
Deep Learning
nerual network
CRF
条件随机场(Conditional Random Field,CRF)
\begin{align}
\end{align}图是由结点及连接结点的编组成的集合。结点记作$v$,结点集合记作$V$;边记作$e$,边的集合记作$E$;图记作$G=\left(V,E\right)$。
概率图模型是由图表示的概率分布。设由联合分布$P\left(Y\right)$,$Y \in \mathcal{Y}$是一组随机变量。由无向图$G=\left(V,E\right)$表示概率分布$P\left(Y\right)$,即在图$G$中,结点$v \in V$表示一个随机变量$Y_{v}$,$Y=\left(Y_
2020-05-05
Machine Learning
nlp
HMM
隐马尔科夫模型(Hidden Markov Model,HMM)
\begin{align}
\end{align}1 隐马尔科夫模型定义状态集合Q=\left\{q_{1},q_{2},\ldots ,q_{N}\right\}
观测集合\begin{align} & V=\left\{v_{1},v_{2},\ldots ,v_{M}\right\} \quad \left| V\right| =M \end{align}
状态序列\begin{align} & I=\left\{i_{1},i_{2},\ldots ,i_{t},\ldots,i_{T}\righ
2020-05-05
Machine Learning
nlp
MCMC
马尔科夫链蒙特卡罗法(Markov Chain Monte Carlo,MCMC)
\begin{align}
\end{align}1 蒙特卡洛法蒙特卡洛法要解决的问题是,假设概率分布的定义已知,通过抽样获得概率分布的随机样本,并通过得到的随机样本对概率分布的特征进行分析。
蒙特卡洛的法有直接抽样法、接受-拒绝抽样法、重要性抽样法等,其核心是随机抽样。
接受-拒绝算法:输入:抽样的目标概率分布的概率密度函数$p\left(x\right)$;输出:概率分布的随机样本$x_1,x_2,\cdots,x_n$。
选择概率密度函数为$q\left(x\right)$的概率分布作为建议分布,使