迁移学习(Transfer Learning)
1 迁移学习的形式化定义
领域$\mathcal{D}$:数据及数据的概率分布
源领域$\mathcal{D}_s=\{\left(\mathbf{x}_i,y_i\right)|P_s\left(\mathbf{x}_i\right)\}_{i=1}^n$
目标领域$\mathcal{D}_t=\{\mathbf{x}_j|P_t\left(\mathbf{x}_j\right)\}_{j=n+1}^{n+m}$
迁移学习(Transfer Learning):给定有标记源领域$\mathcal{D}_s=\{\left(\mathbf{x}_i,y_i\right)|P_s\left(\mathbf{x}_i\right)\}_{i=1}^n$和无标记目标领域$\mathcal{D}_t=\{\mathbf{x}_j|P_t\left(\mathbf{x}_j\right)\}_{j=n+1}^{n+m}$,其中$P_s\left(\mathbf{x}_i\right)\neq P_t\left(\mathbf{x}_j\right)$。迁移学习的目的是借助源领域$\mathcal{D}_s$的知识,来学习目标领域$\mathcal{D}_t$的知识(标签)。
领域自适应(Domain Adaptation):给定有标记源领域$\mathcal{D}_s=\{\left(\mathbf{x}_i,y_i\right)|P_s\left(\mathbf{x}_i\right)\}_{i=1}^n$和无标记目标领域$\mathcal{D}_t=\{\mathbf{x}_j|P_t\left(\mathbf{x}_j\right)\}_{j=n+1}^{n+m}$,
其中,$\mathbf{x}_i\in\mathcal{X}_s,\mathbf{x}_j\in\mathcal{X}_t$,且$\mathcal{X}_s=\mathcal{X}_t,P_s\left(\mathbf{x}_i\right)\neq P\left(\mathbf{x}_j\right)$;$y_i\in\mathcal{Y}_s,y_j\in\mathcal{Y}_t$,且$\mathcal{Y}_s=\mathcal{Y}_t,Q_s\left(y_i|\mathbf{x}_i\right)= Q\left(y_j|\mathbf{x}_j\right)$。
迁移学习的目的是,利用有标记源领域数据$\mathcal{D}_s$学习一个分类器$f:\mathbf{x}_s\to y_s$来预测目标领域数据$\mathcal{D}_t$的标签$y_t\in\mathcal{Y}_t$。
度量是描述源领域$\mathcal{D}_s$和目标领域$\mathcal{D}_t$之间的距离。
最大均值差异(Maximum mean discrepancy,MMD),度量再生希尔伯特空间中两个分布的距离,是一种核学习方法。
其中,$\phi\left(\cdot\right)$是将数据映射到满足$\left
2 迁移学习方法
边缘分布自适应
边缘分布自适应的目标是减少源领域$\mathcal{D}_s$和目标领域$\mathcal{D}_t$之间的边缘概率分布的距离,从而完成迁移学习。
边缘分布自适应方法使用$P_s\left(\mathbf{x}\right)$和$P_t\left(\mathbf{x}\right)$之间的距离来近似两个领域之间的差异:
迁移成分分析(Transfer Component Aualysis,TCA)
由于$P_s\left(\mathbf{x}\right)\neq P_t\left(\mathbf{x}\right)$,假设存在映射$\phi\left(\cdot\right)$,使得$P_s\left(\phi(\left(\mathbf{x}\right)\right)\approx P_t\left(\phi\left(\mathbf{x}\right)\right)$,则$P\left(y_s|\phi\left(\mathbf{x}_s\right)\right)\approx P\left(y_t|\phi\left(\mathbf{x}_t\right)\right)$。
迁移成分分析中,源领域与目标领域之间的距离度量
其中,$n_1,n_2$分别为源领域与目标领域的样本个数。
引入核矩阵
其中,$K_{\cdot,\cdot}=K\left(\mathbf{x}_\cdot,\mathbf{x}_\cdot\right)$
系数矩阵$L=\left(l_{ij}\right)$
其中,
则
其中,$\mathop{tr}\left(\cdot\right)$为矩阵的迹
条件分布自适应
条件分布自适应的目标是减少源领域$\mathcal{D}_s$和目标领域$\mathcal{D}_t$之间的条件概率分布的距离,从而完成迁移学习。
条件分布自适应方法使用$Q_s\left(y_s|\mathbf{x}_s\right)$和$Q_t\left(y_t|\mathbf{x}_t\right)$之间的距离来近似两个领域之间的差异:
联合分布自适应
联合分布自适应的目标是减少源领域$\mathcal{D}_s$和目标领域$\mathcal{D}_t$之间的联合概率分布的距离,从而完成迁移学习。
联合分布自适应方法使用$P_s\left(\mathbf{x}\right)$和$P_t\left(\mathbf{x}\right)$之间的距离以及$Q_s\left(y_s|\mathbf{x}_s\right)$和$Q_t\left(y_t|\mathbf{x}_t\right)$之间的距离来近似两个领域之间的差异:
3 深度迁移学习
损失函数
其中,$l_c\left(\mathcal{D}_s,y_s\right)$为网络模型在源领域的损失,$l_A\left(\mathcal{D}_s,\mathcal{D}_t\right)$为网络模型的自适应损失。
深度领域混淆(Deep Domain Confusion,DDC)
损失函数
其中,$MMD$为最大值均方差异。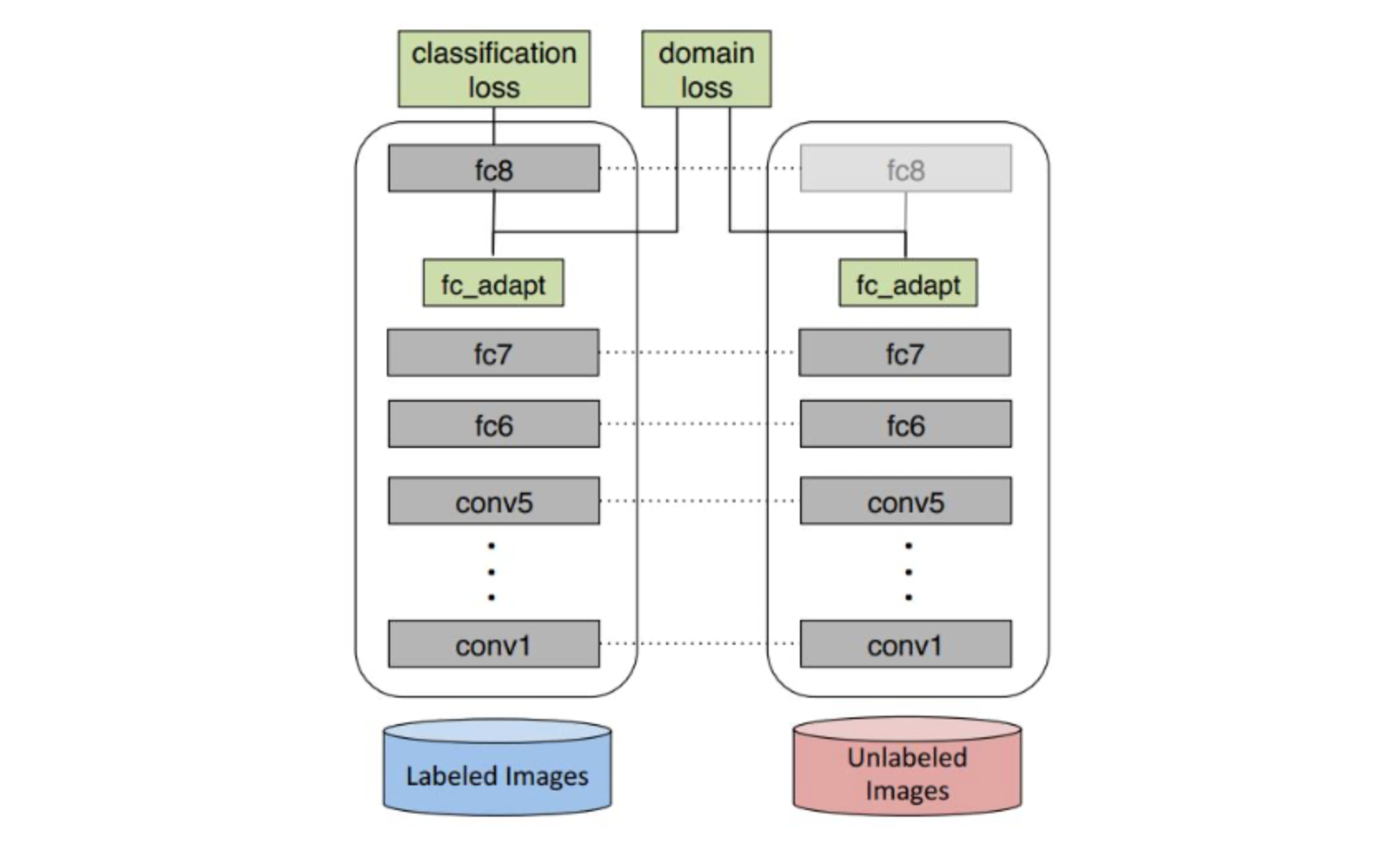
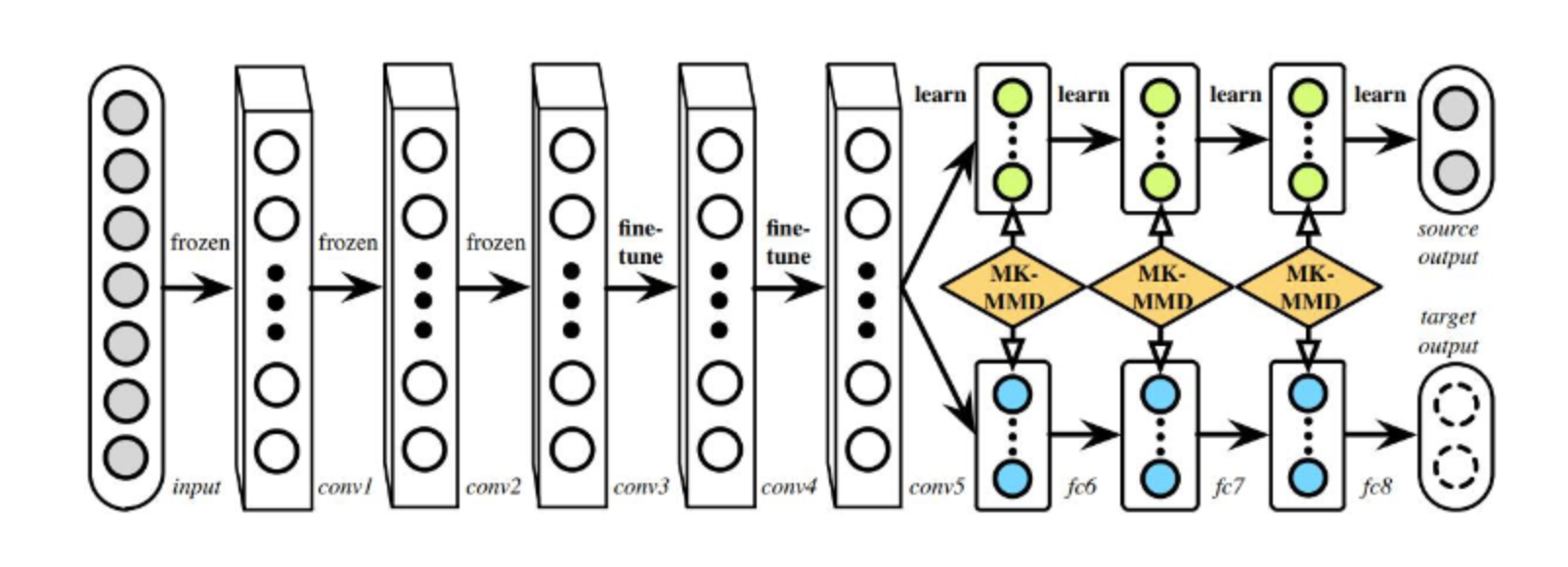
深度适应网络(Deep Adaptation Networks,DAN)
多核MMD
优化目标
深度对抗网络迁移
生成对抗网络GAN
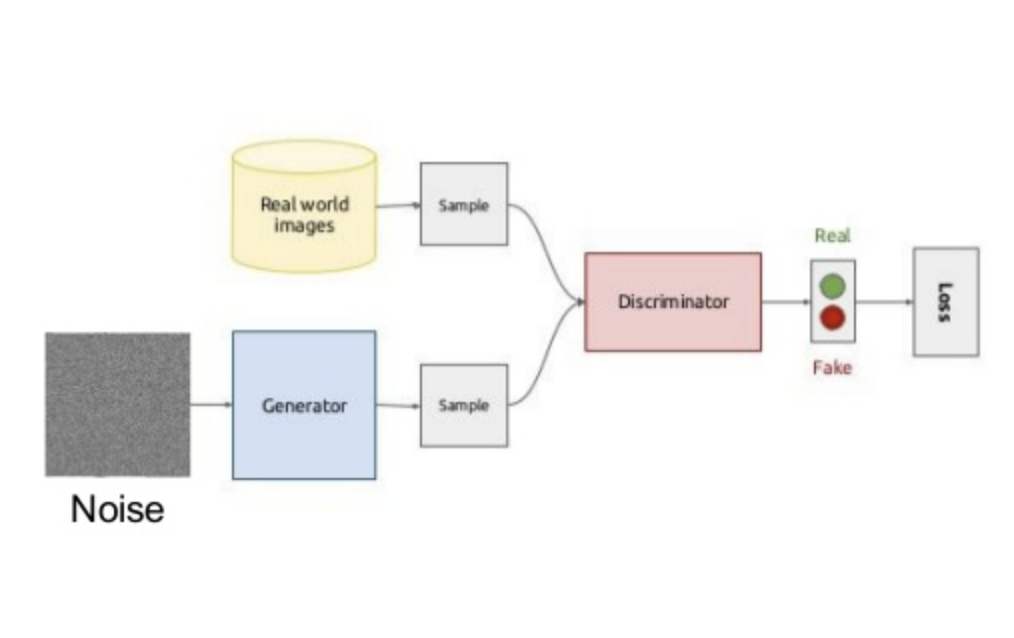
目标函数:
其中,$\mathbf{x}$为服从分布$p_{data}\left(\mathbf{x}\right)$的样本数据,$\mathbf{z}$为服从先验分布$p_\mathbf{z}\left(\mathbf{z}\right)$的输入随机噪声变量,生成器$G\left(\cdot\right)$为多层感知机表示的输入随机噪声变量到数据空间的映射函数,$G\left(\mathbf{z}\right)\sim p_G$服从从样本数据$\mathbf{x}$学习到的分布$p_G$,判别器$D\left(\cdot\right)$为多层感知机表示的区分数据分布$p_{data}$还是生成器分布$p_G$的判别函数。
优化问题:
领域对抗神经网络(Domain-Adversarial Neural Network,DANN)
生成器进行源领域与目标领域特征提取,使得判别器无法对两个领域的差异进行判别。
领域对抗损失函数
其中$\mathcal{L}_d$表示为
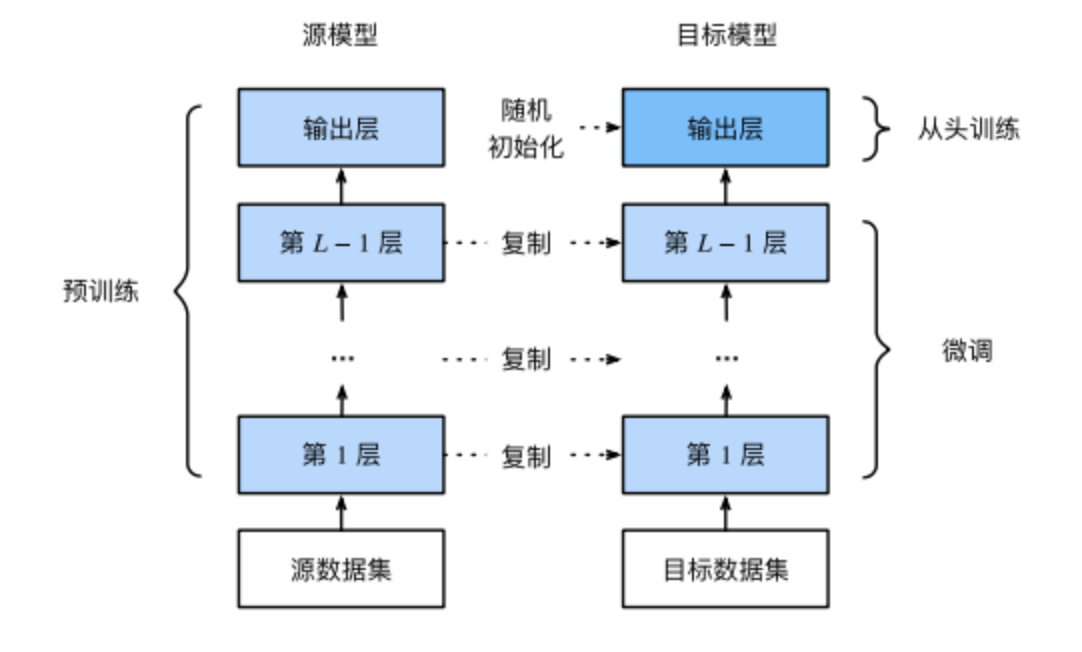
微调网络 finetune
4 参考文献
Li, Y., Wang, N., Shi, J., Hou, X., and Liu, J. (2018). Adaptive batch normalization for practical domain adaptation. Pattern Recognition, 80:109–117.
Long, M., Cao, Y., Wang, J., and Jordan, M. (2015a). Learning transferable features with deep adaptation networks. In ICML, pages 97–105.
Tzeng, E., Hoffman, J., Darrell, T., and Saenko, K. (2015). Simultaneous deep transfer across domains and tasks. In Proceedings of the IEEE International Conference on Computer Vision, pages 4068–4076, Santiago, Chile. IEEE.
Tzeng, E., Hoffman, J., Saenko, K., and Darrell, T. (2017). Adversarial discriminative domain adaptation. In CVPR, pages 2962–2971.
Tzeng, E., Hoffman, J., Zhang, N., et al. (2014). Deep domain confusion: Maximizing for domain invariance. arXiv preprint arXiv:1412.3474.
Bousmalis, K., Trigeorgis, G., Silberman, N., Krishnan, D., and Erhan, D. (2016). Domain separation networks. In Advances in Neural Information Processing Systems, pages 343–351.
Shen, J., Qu, Y., Zhang, W., and Yu, Y. (2018). Wasserstein distance guided representation learning for domain adaptation. In AAAI.
Deep Learning domain adaptation finetune
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!