A Neural Probabilistic Language Model
1 统计语言模型与n-gram模型
统计语言模型可描述为给定前序词序列后,下一单词出现的条件概率的乘积:
其中,$w_t$是第$t$个单词,$w_i^j=\left(w_i,w_{i+1},\dots,w_{j-1},w_j\right)$是从第$i$个单词到第$j$个单词的子序列。
n-gram模型可描述为给定前$n-1$个单词后,第$n$个单词出现的条件概率:
2 神经网络语言模型
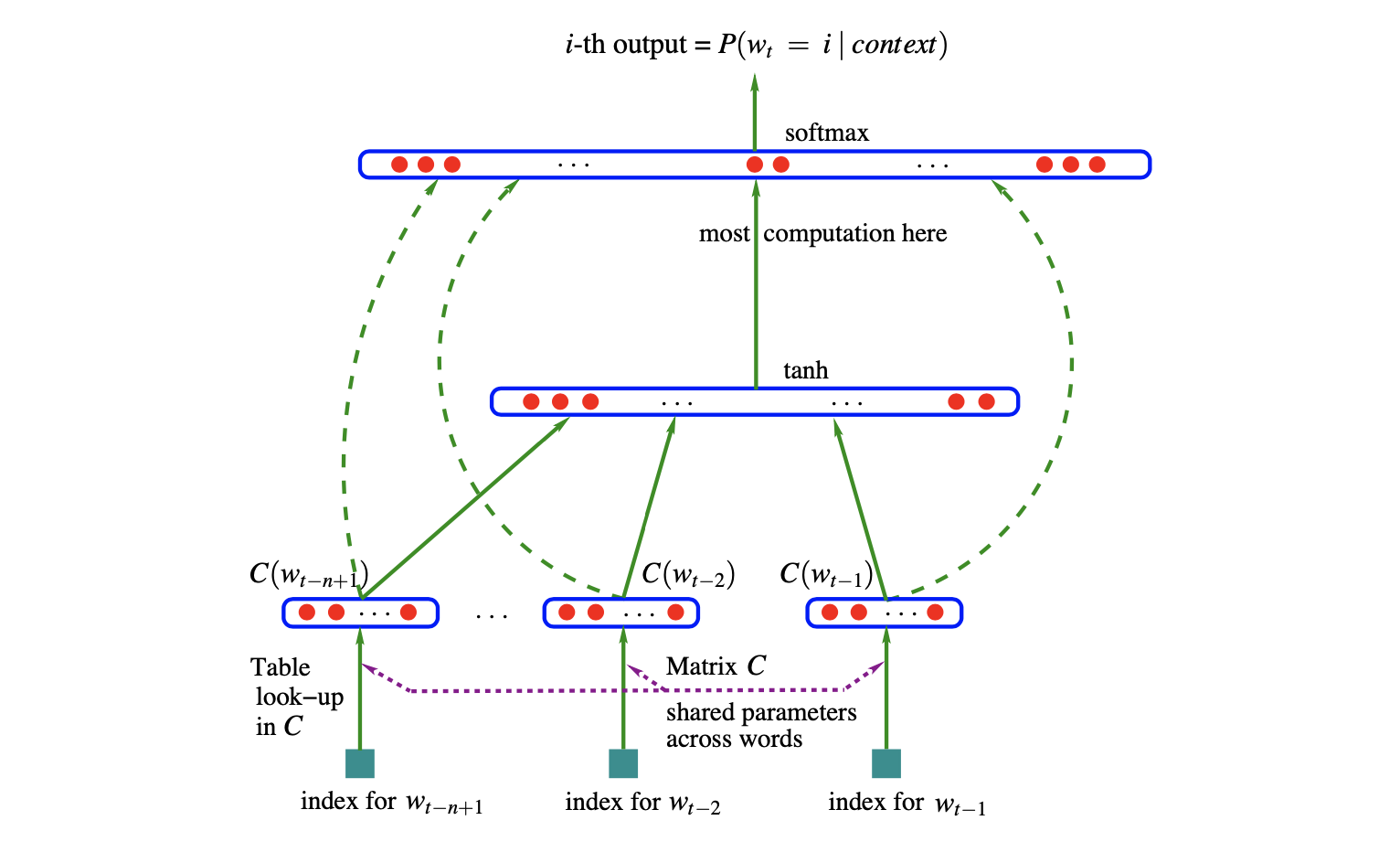
训练集$w_1,w_2,\dots,w_T$是单词序列。单词表$V$是由单词组成的规模很大但是有限的集合,$w_t\in V$,$|V|$是单词表$V$中单词个数。
学习的目标
需要满足的约束条件:
- $f\left(w_t,w_{t-1},\dots,w_{t-n+2},w_{t-n+1}\right)>0$
- $\sum_{i=1}^{|V|}f\left(i,w_{t-1},\dots,w_{t-n+2},w_{t-n+1}\right)=1$
将函数$f\left(w_t,w_{t-1},\dots,w_{t-n+2},w_{t-n+1}\right)=\hat P\left(w_t|w_1^{t-1}\right)$分解为两部分:
- 从单词表$V$中任意元素$i$到实向量$C\left(i\right)\in\mathbb{R}^m$的映射$C$。映射$C$表示单词表中每个单词的分布式特征向量。在实践中,映射$C$表示为一个$|V|\times m$的自由参数矩阵;
- 使用映射$C$表达的每个单词的概率函数$g$。概率函数$g$是从输入词序列的单词上下文特征向量$\left(C\left(w_{t-n+1}\right),\dots,C\left(w_{t-1}\right)\right)$,到下一单词$w_t$的条件概率分布的映射。概率函数$g$的输出是一个向量,向量中第$i$个元素是概率$\hat P\left(w_t=i|w_1^{t-1}\right)$
函数$f$是两个映射$C$和$g$的组合。这两个映射都与各自的参数关联。映射$C$的参数是特征向量本身,被表示为一个$|V|\times m$的矩阵,矩阵的第$i$行是单词$i$的特征向量。函数$g$可以被一个基于参数集$\omega$的前馈神经网络或者卷积神经网络实现或其他参数化函数实现。则整体参数集合是$\theta=\left(C,\omega\right)$。
训练是通过寻找能够使最大化语料库的带罚项对数似然的$\theta$实现的:
其中,$R\left(\theta\right)$是正则化项,是权重的惩罚。
神经网络在单词特征映射之后有一个隐藏层,并且可以选择将单词特征直接连接到输出层。因此,实际上有两个隐藏层,共享的单词特征映射层$C$和普通的双曲正切隐藏层。神经网络输出层采用$softmax$输出层,
其中,$y_i$是每个输出单词$i$的未归一化的$\log$概率。
使用参数$b,W,U,d,H$计算每个输出单词$i$的未归一化的$\log$概率
其中,$x$是单词特征层激活向量,由矩阵C中的输入单词特征串联组成
令$h$为隐藏单元个数,$m$为每个单词的特征维数。当没有从单词特征到输出的直接连接时,矩阵$W$设置为$\mathbf{0}$。模型自由参数包括:输出偏置向量$b\in\mathbb{R}^{|V|}$,隐藏层偏置向量$d\in\mathbb{R}^h$,隐藏层到输出层权值矩阵$U\in\mathbb{R}^{|V|\times h}$,单词特征输出权值矩阵$W\in\mathbb{R}^{|V|\times\left(n-1\right)\cdot m}$,隐藏层权值矩阵$H\in\mathbb{R}^{h\times\left(n-1\right)\cdot m}$,单词特征矩阵$C\in\mathbb{R}^{|V|\times m}$
自由参数共有$h\left(1+\left(n-1\right)m\right)+|V|\left(1+nm+h\right)$个。
神经网络上的随机梯度提升是指在训练语料库的第$t$个单词后进行以下迭代更新
其中,$\varepsilon$是学习率。
第$i$个处理器,第$t$个样本的计算:
前向计算
(a)单词特征层执行前向计算:(b)隐藏层执行前向计算:
(c)在第$i$个块内的输出结点执行前向计算:
$\quad\qquad在第i个块中使用下标j进行循环$
$\quad\qquad如果有直接连接,y_j\leftarrow y_j+xW_j$
(d)在所有处理器中计算并分享$S=\sum_i s_i$
(e)概率规范化
$\quad\qquad在第i个块中使用下标j进行循环$(f)更新$\log$似然函数。
后向计算与参数更新(学习率$\varepsilon$)
(a)第$i$个块内的输出结点进行后向梯度计算:
$\quad\qquad清空梯度向量\frac{\partial L}{\partial a}和\frac{\partial L}{\partial x}$
$\quad\qquad在第i个块中使用下标j进行循环$$\quad\qquad如果有直接连接,\frac{\partial L}{\partial x}\leftarrow\frac{\partial L}{\partial x}+\frac{\partial L}{\partial y_j}W_j$
$\quad\qquad如果有直接连接,W_j\leftarrow W_j+\varepsilon\frac{\partial L}{\partial y_j}x$
(b)在所有处理器中计算并分享$\frac{\partial L}{\partial x}$和$\frac{\partial L}{\partial a}$
(c)后向传播并更新隐藏层权值:
$\quad\qquad在1和h之间使用下标k进行循环$(d)更新单词特征向量:
$\quad\qquad在1和n-1之间使用下标k进行循环$$\quad\qquad其中,\frac{\partial L}{\partial x\left(k\right)}是\frac{\partial L}{\partial x}的第k个分量$。
Deep Learning nlp language model
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!