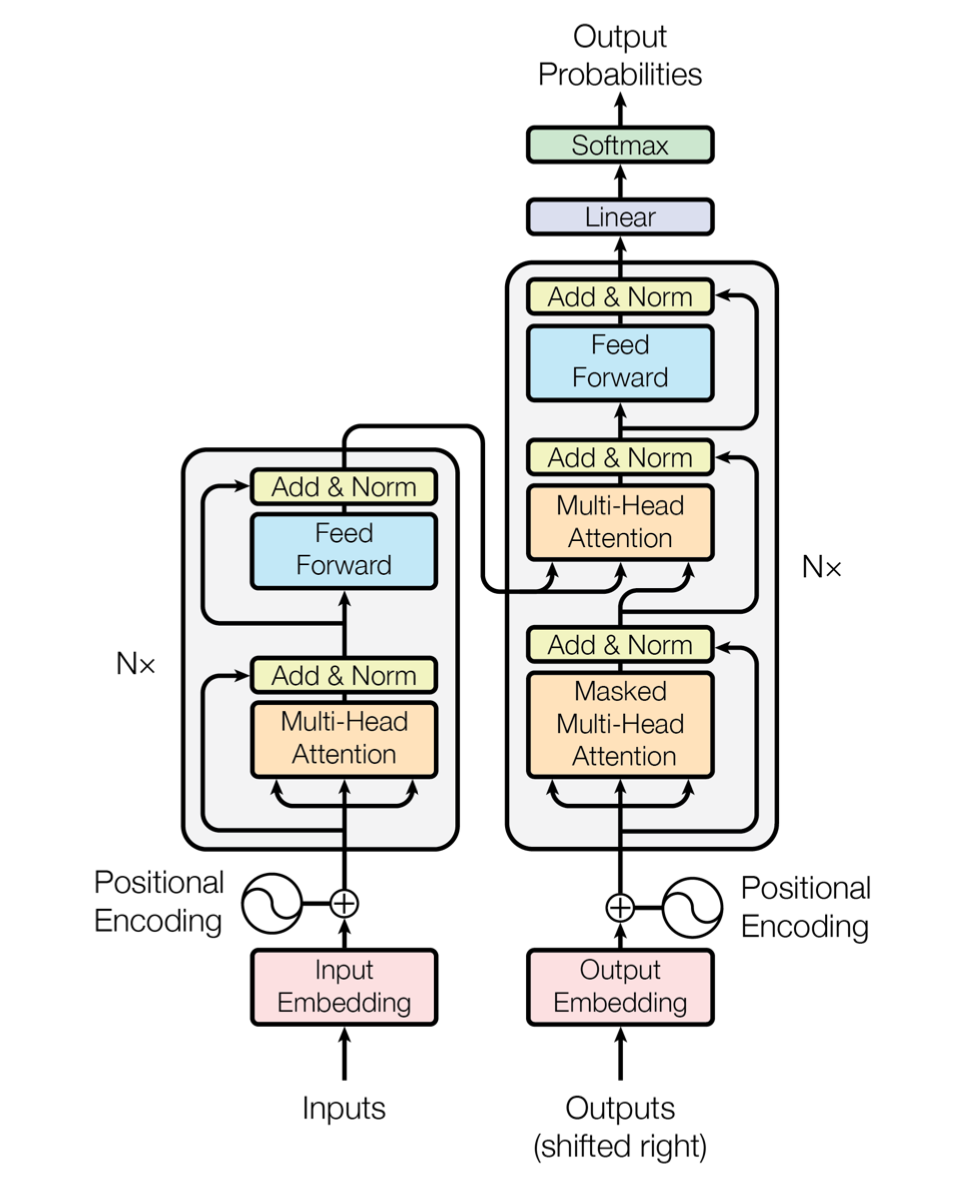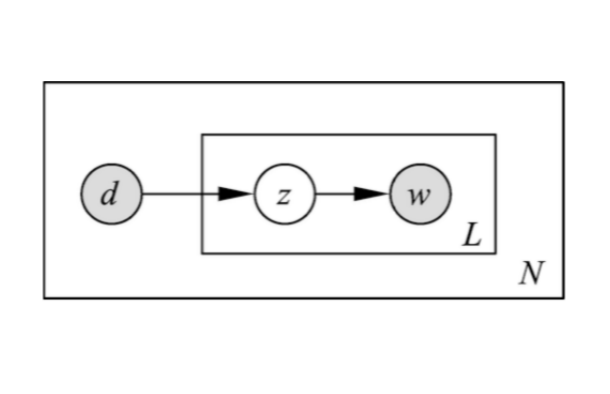
pLSA
概率潜在语义分析(Probabilistic Latent Semantic Analysis, PLSA)
\begin{align}
\end{align}单词集合$W=\{w_1,w_2,\cdots,w_M\}$文本集合$D=\{d_1,d_2,\cdots,d_N\}$话题集合$Z=\{z_1,z_2,\cdots,z_K\}$单词-文本共现数据$T=\left[n\left(w_i,d_j\right)\right],i=1,2,\cdots,M;j=1,2,\cdots,N;$
文本-单词共现数据的生成过程:
依据概率分布$P\left(d\right)$,从文本集合中随机选取

LSA
潜在语义分析(Latent Semantic Analysis, LSA)
\begin{align}
\end{align}向量空间模型:给定一个文本,用一个向量表示该文本的”语义“,向量的每以一维对应一个单词,其数值为该单词在文本中出现的频数或权值。
基本假设:
文本中所有单词出现的情况表示了文本的语义内容;
文本集合中的每个文本都表示为一个向量,存在于一个向量空间;
向量空间的度量,如内积或标准化内积表示文本之间的”语义相似度“。
文本集合$D=\{d_1,d_2,\cdots,d_n\}$单词集合$W=\{w_1,w_2,\cdots,w_m\}$
单词向量空间:单词-文本矩阵
X
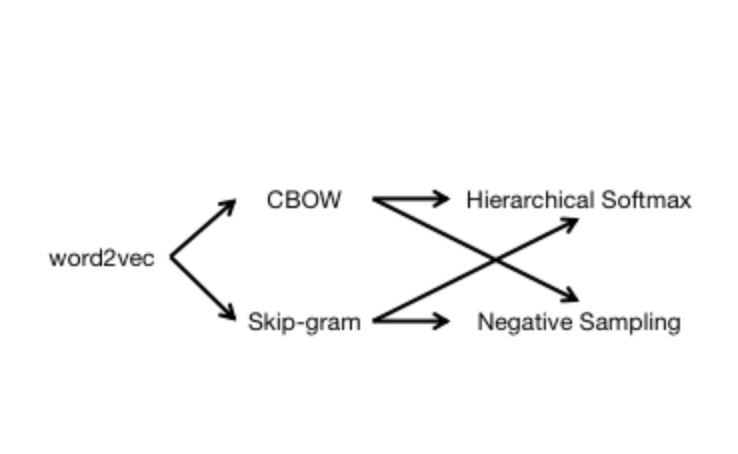
word2vec
word2vec
\begin{align}
\end{align}
1 连续词袋模型(CBOW)与跳字模型(Skip-gram)单词$w$;词典$\mathcal{D}=\{w_1,w_2,\dots,w_N\}$,由单词组成的集合;语料库$\mathcal{C}$,由单词组成的文本序列;单词$w_t$的上下文是语料库中由单词$w_t$的前$c$个单词和后$c$个单词组成的文本序列,$w_t$称为中心词。
Context\left(w_t\right)=\left(w_{t-c},\cdots,w_{t-2},w_{t-1},w_{t+1},w_{t+2},\cdots,w_{t+c}\ri
2020-05-03
Deep Learning
nlp
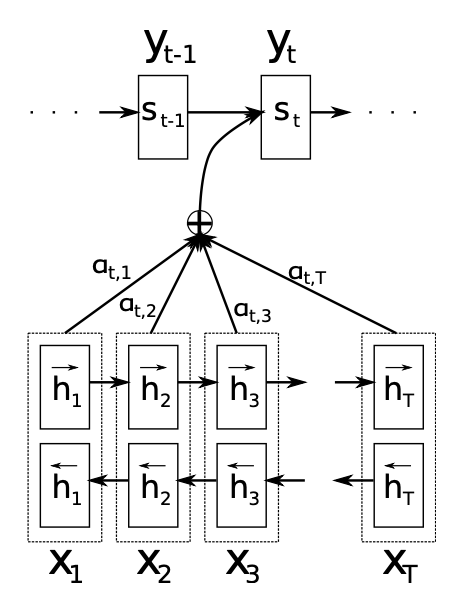
seq2seq_with_attention
Seq2Seq with Attention
\begin{align}
\end{align}1 序列到序列任务中的注意力机制Seq2Seq with Attention网络架构
seq2seq with Attention神经网络架构中,编码器采用双向循环神经网络学习将输入序列$\mathbf{x}$编码成每个时刻的上下文向量(注意力分布)$c_i$,解码器学习将上下文向量$c_i$解码为输出序列$\mathbf{y}$。
源文本序列:$\mathbf{x}=\left(x_1,\cdots,x_{T_x}\right)$,其中$x_i\in\mathbb{R}^{K_x}$为one-of
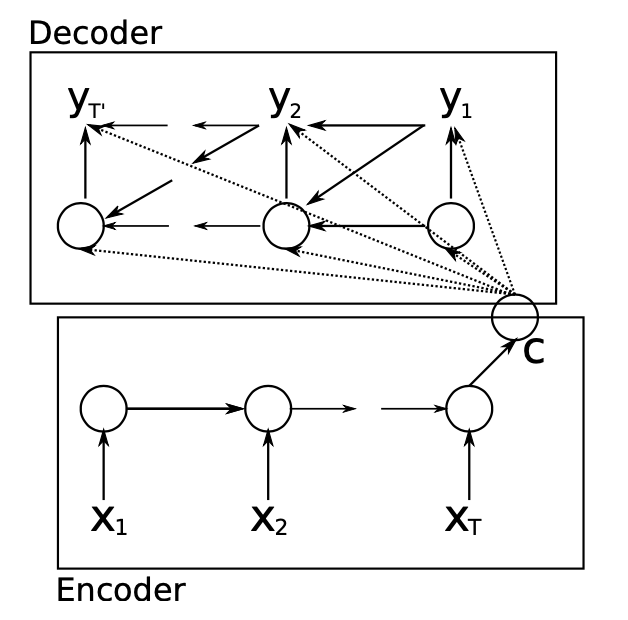
seq2seq_with_Encoder-Decoder
seq2seq with Encoder-Decoder
\begin{align}
\end{align}1 RNN Encoder-Decoder神经网络架构
RNN Encoder-Decoder神经网络架构使用循环神经网络学习将变长源序列$X$编码成定长向量表示$\mathbf{c}$,并将学习的定长向量表示$\mathbf{c}$解码成变长目标序列$Y$。模型的编码器和解码器被联合训练,以最大化给定源序列的目标序列的条件概率。
源文本序列:$X=\left(\mathbf{x}_{1}, \mathbf{x}_{2}, \dots, \mathbf{x}_{N}\right)$其中,