生成对抗网络(Generative Adversarial Networks)
1. GAN生成对抗网络的原理及实现
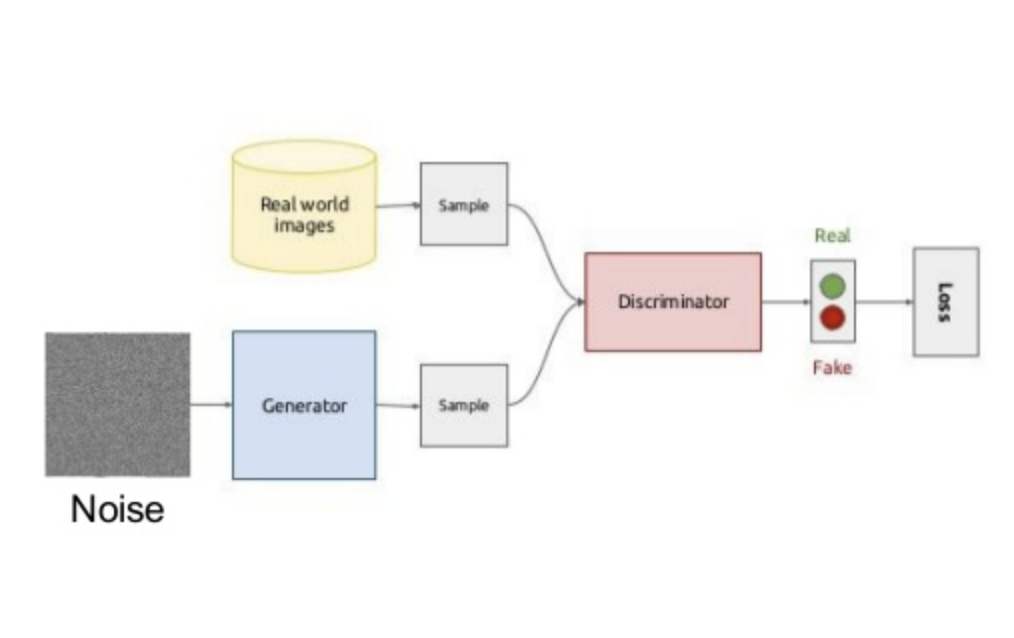
模型结构及优化
目标函数:
其中,$\mathbf{x}$为服从分布$p_{data}\left(\mathbf{x}\right)$的样本数据,$\mathbf{z}$为服从先验分布$p_\mathbf{z}\left(\mathbf{z}\right)$的输入随机噪声变量,生成器$G\left(\cdot\right)$为多层感知机表示的输入随机噪声变量到数据空间的映射函数,$G\left(\mathbf{z}\right)\sim p_G$服从从样本数据$\mathbf{x}$学习到的分布$p_G$,判别器$D\left(\cdot\right)$为多层感知机表示的区分数据分布$p_{data}$还是生成器分布$p_G$的判别函数。
优化问题:
给定任意生成器$G$,判别器$D$的训练目标是最大化目标函数$V\left(G,D\right)$
令
得最优判别器
将最优判别器$D_G^{*}\left(\mathbf{x}\right)$代入,得目标函数
优化问题:
由于$p_{data}$和$p_G$两个分布的JS散度是非负的,当且仅当$p_{data}=p_G$时JS散度等于$0$,目标函数$C\left(G\right)$的最小值为$C^{*}=-2\log2$,即生成器完整的复现了数据的生成过程。
小批量随机梯度下降训练算法
生成对抗网络的小批量随机梯度下降训练算法:
输入:数据分布$p_{data}\left(\mathbf{x}\right)$,输入噪声先验分布$p_\mathbf{z}\left(\mathbf{z}\right)$,训练轮次$n$,判别器训练步数$k$,小批量$m$;
输出:判别器$D\left(\mathbf{x};\theta_d\right)$和生成器$G\left(\mathbf{z};\theta_g\right)$
for 训练轮次$n$ do
1.1 for 判别器训练步数$k$ do
1.1.1 从输入噪声分布$p_\mathbf{z}\left(\mathbf{z}\right)$生成$m$个小样本噪声样本$\left\{\mathbf{z}^{\left(1\right)},\cdots,\mathbf{z}^{\left(m\right)}\right\}$
1.1.2 从数据分布$p_{data}\left(\mathbf{z}\right)$生成$m$个小样本数据$\left\{\mathbf{x}^{\left(1\right)},\cdots,\mathbf{x}^{\left(m\right)}\right\}$
1.1.3 通过增加随机梯度更新判别器1.2 end for
1.3 从输入噪声分布$p_\mathbf{z}\left(\mathbf{z}\right)$生成$m$个小样本噪声样本$\left\{\mathbf{z}^{\left(1\right)},\cdots,\mathbf{z}^{\left(m\right)}\right\}$
1.4 通过降低随机梯度更新生成器end for
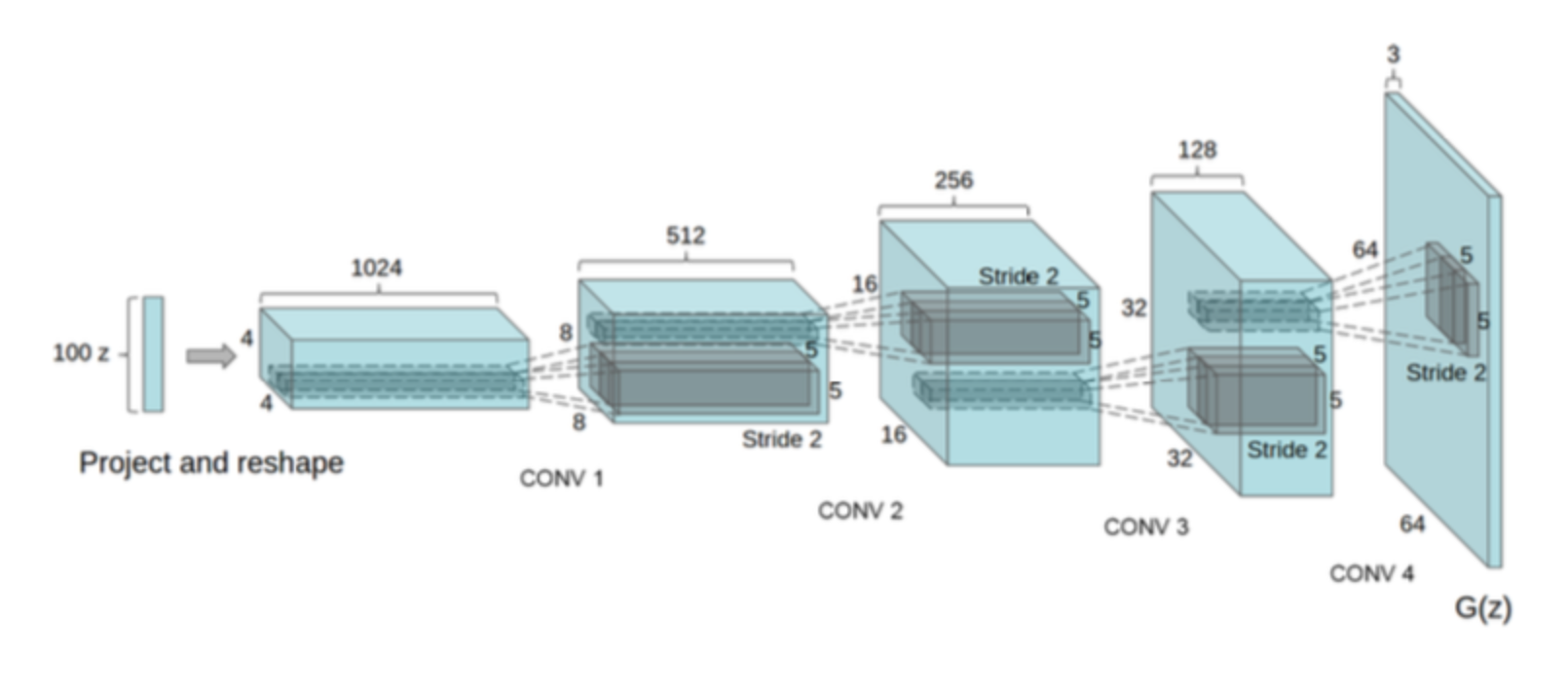
2 深度卷积生成对抗网络
模型架构特点
- 判别器中使用跨步卷积(strided convolutions)替换池化层;生成器中使用微步卷积(fractional-strided convolutions)替换池化层;
- 判别器和生成器都使用批归一化;
- 判别器和生成器都移除全连接隐层;
- 生成器中的所有层都使用ReLU激活函数,但输出层除外,后者使用Tanh激活函数;
- 判别器中的所有层都使用LeakyReLU激活函数。
3. 生成对抗网络的改进及发展
对数据分布$p_{data}$和生成分布$p_G$加入噪声
当数据分布$p_{datea}$与生成分布$p_G$的支撑集是高维空间中的低维流形时,$p_{data}$与$p_G$重叠部分测度为$0$的概率为$1$,即分布$p_{data}$与分布$p_G$没有重叠或重叠非常少。而当分布$p_{data}$与分布$p_G$没有重叠或重叠非常少时,JS散度为常量,很难衡量两个分布的距离。使得生成器$G\left(\mathbf{z}\right)$的梯度为$0$,造成梯度消失。
目标函数:
其中,$p_{data+\epsilon}$为加入噪声后的数据分布,$p_{G+\epsilon}$为加入噪声后的生成分布。
使用Wasserstein距离进行分布度量
Wasserstein距离(Earth-Mover距离):
其中,$\Gamma\left(p_{data},p_G\right)$为分布$p_{data}$与$p_G$的所有可能的联合分布集合,$d\left(\mathbf{x},\mathbf{y}\right)$为$\mathbf{x}$和$\mathbf{y}$之间的欧氏距离。

由于Wasserstein距离可表示为
其中,$|f|_L$为函数$f$的Lipschitz常数。
所以可得
其中,$f_w$为由参数$w$表示的函数。
WGAN生成器损失:
WGAN判别器损失:
4参考资料:
《Generative Adversarial Nets》
《UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS》
《Wasserstein GAN》