Transformer特征提取器
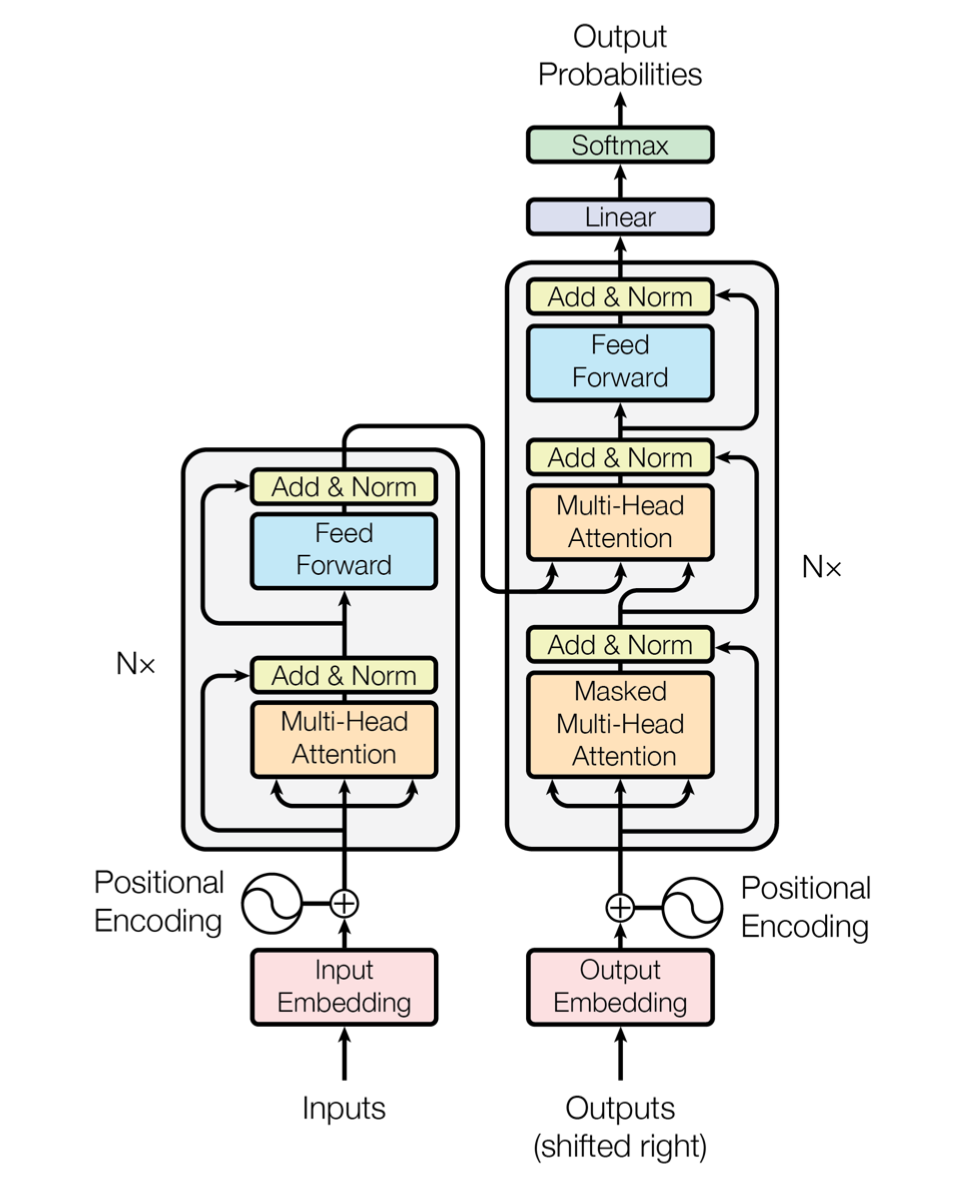
1 输入序列、目标序列与输出序列
输入序列$inputs=\left(i_1,i_2,\cdots,i_p,\cdots,i_N\right)$,其中$i_p\in\mathbb{N}$为输入符号表中的序号。
目标序列$targets=\left(t_1,t_2,\cdots,t_q,\cdots,t_M\right)$,其中$t_q\in\mathbb{N}$为目标符号表中的序号。
其中,$outputs_probabilities=\left(o_1,o_2,\cdots,o_q,\cdots,o_M\right)$为预测序列,$o_q\in\mathbb{N*}$为目标符号表中的序号。
在自然语言处理任务中,当输入序列与目标序列中的元素较多,通常以句子为单位划分为若干个对应的“输入-目标”子序列进行学习。
2 词嵌入与位置编码
输入序列词嵌入与位置编码
输入序列词嵌入$Embedding\left(inputs\right)\in\mathbb{R}^{N\times d_{model}}$,其中,$N$为输入序列长度,$d_{model}$为词嵌入维度。
输入序列位置编码$Pos_Enc\left(inputs_position\right)\in\mathbb{R}^{N\times d_{model}}$,
其中,$inputs_position=\left(1,2,\cdots,p,\cdots,N\right)$为输入序列中输入符号对应的位置序号;
其中,$pos\in inputs_position,i\in\left(0,1,\cdots,d_{model}/2\right)$。
目标序列词嵌入与位置编码
目标序列词嵌入$Embedding\left(targets\right)\in\mathbb{R}^{M\times d_{model}}$,其中$M$为目标序列长度,$d_{model}$为词嵌入维度。
目标序列位置编码$Pos_Enc\left(targets_position\right)\in\mathbb{R}^{M\times d_{model}}$,
其中,$targets_position=\left(1,2,\cdots,q,\cdots,M\right)$为目标序列的位置序号。
3 编码器Encoder
编码器结构
编码器结构:
其中,$e_0\in\mathbb{R}^{N\times d_{model}}$为编码器输入,$EncoderLayer\left(\cdot\right)$为编码器层,$n$为层数,$e_l\in\mathbb{R}^{N\times d_{model}}$为第$l$层编码器层输出。
编码器层EncoderLayer:
其中,$e_{in}\in\mathbb{R}^{N\times d_{model}}$为编码器层输入,$e_{out}\in\mathbb{R}^{N\times d_{model}}$为编码器层输出,$MultiHeadAttention\left(\cdot\right)$为多头注意力机制,$FFN\left(\cdot\right)$为前馈神经网络,$LayerNorm\left(\cdot\right)$为层归一化。
多头注意力机制与缩放点积

输入向量序列$e_{in}=\left(e_{in1},e_{in2},\cdots,e_{inN}\right)\in\mathbb{R}^{N\times d_{model}}$,分别得到查询向量序列$Q=e_{in}$,键向量序列$K=e_{in}$,值向量序列$V=e_{in}$。
多头注意力机制
其中,多头输出$head_i=Attention\left(QW_i^Q,KW_i^K,VW_i^V\right)$,可学习的参数矩阵$W_i^Q\in\mathbb{R}^{d_{model}\times d_k},W_i^K\in\mathbb{R}^{d_{model}\times d_k},W_i^V\in\mathbb{R}^{d_{model}\times d_v},W^O\in\mathbb{R}^{hd_v\times d_{model}}$
使用缩放点积作为打分函数的自注意力机制
编码器pad掩码
其中,
$enc_pad_mask\in\mathbb{R}^{N\times N}$,$i_p$为输入序列$inputs$对应位置序号。
前馈神经网络
其中,参数矩阵$W_1\in\mathbb{R}^{d_{model}\times d_{ff}},W_2\in\mathbb{R}^{d_{ff}\times d_{model}}$,偏置$b_1\in\mathbb{R}^{d_{ff}},b_2\in\mathbb{R}^{d_{model}}$。
4 解码器Decoder
解码器结构
其中,$d_0\in\mathbb{R}^{M\times d_{model}}$为解码器输入,$DecoderLayer\left(\cdot\right)$为解码器层,$n$为层数,$d_l\in\mathbb{R}^{M\times d_{model}}$为第$l$层解码器层输出,$W\in\mathbb{R}^{M\times tgt_vocab_size}$输入输出参数矩阵,$softmax\left(\cdot\right)$为softmax层。
解码器层DecoderLayer:
其中,$d_{in}\in\mathbb{R}^{M\times d_{model}}$为解码器层输入,$d_{out}\in\mathbb{R}^{M\times d_{model}}$为解码器层输出,$MultiHeadAttention\left(\cdot\right)$为多头注意力机制,$FFN\left(\cdot\right)$为前馈神经网络,$LayerNorm\left(\cdot\right)$为层归一化。
解码器pad掩码、解码器sequence掩码和编码器解码器pad掩码
解码器pad掩码
其中,
$dec_pad_mask\in\mathbb{R}^{M\times M}$,$t_q$为目标序列$targets$对应位置序号。
解码器sequence掩码
其中,
$dec_sequence_mask\in\mathbb{R}^{M\times M}$,为非零元素为1的上三角矩阵。
解码器掩码
编码器解码器pad掩码
其中,
$dec_enc_pad_mask\in\mathbb{R}^{M\times N}$,$i_p$为输入序列$inputs$对应位置序号。
Deep Learning nlp multi-head attention encoder-decoder self attention
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!