seq2seq with Encoder-Decoder
1 RNN Encoder-Decoder神经网络架构
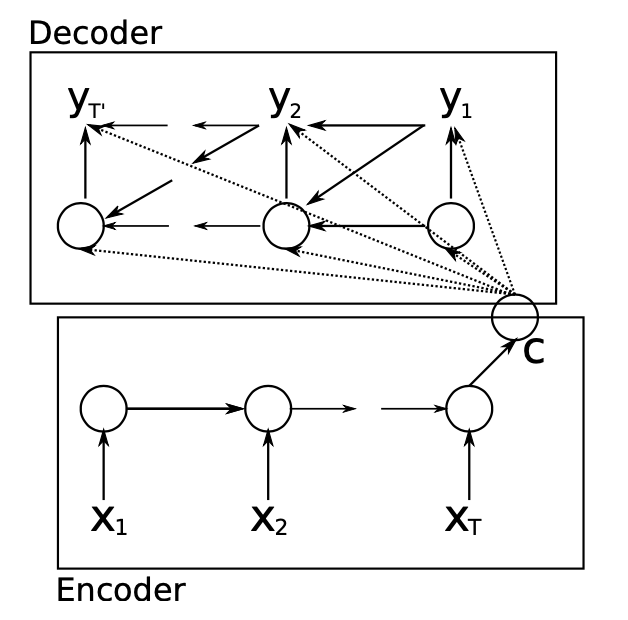
RNN Encoder-Decoder神经网络架构使用循环神经网络学习将变长源序列$X$编码成定长向量表示$\mathbf{c}$,并将学习的定长向量表示$\mathbf{c}$解码成变长目标序列$Y$。模型的编码器和解码器被联合训练,以最大化给定源序列的目标序列的条件概率。
源文本序列:$X=\left(\mathbf{x}_{1}, \mathbf{x}_{2}, \dots, \mathbf{x}_{N}\right)$
其中,$\mathbf{x}_i=\left(l_1,l_2,\cdots,l_j,\cdots,l_K\right)$,其中$l_j=I\left(i=j\right),\quad\left(j=1,\cdots,K\right)$。
目标文本序列:$Y=\left(\mathbf{y}_{1}, \mathbf{y}_{2}, \dots, \mathbf{y}_{M}\right)$
其中,$\mathbf{y}_i=\left(l_1,l_2,\cdots,l_j,\cdots,l_K\right)$,其中$l_j=\left(i=j\right),\quad\left(j=1,\cdots,K\right)$
最大化条件似然函数
其中,$\theta$是模型参数,$\left(\mathbf{y}_n,\mathbf{x}_n\right)$输入输出、输入序列对。
2 编码器Encoder
源文本单词的词嵌入表示:$e\left(\mathbf{x}_i\right)\in\mathbb{R}^{500}$
编码器的隐藏状态由1000个隐藏单元组成。
编码器隐藏状态初始化,在$t=0$时刻第$j$个隐藏单元
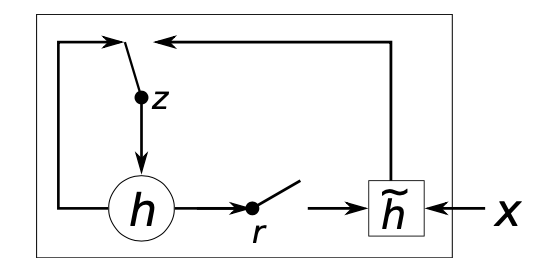
在$t$时刻第$j$个隐藏单元
其中,
$\sigma\left(\cdot\right)$为sigmoid函数,$\odot$为向量元素乘法,$\mathbf{W},\mathbf{W}_z,\mathbf{W}_r\in\mathbb{R}^{1000\times 500}$和$\mathbf{U},\mathbf{U}_z,\mathbf{U}_r\in\mathbb{R}^{1000\times 1000}$为权值矩阵。为了使方程齐整,省略了偏置项。
源文本最后第$N$时刻,编码器的隐藏状态计算完成,源文本的定长向量表示
其中,$\mathbf{V}\in\mathbb{R}^{1000\times 1000}$为权值矩阵。
3 解码器Decoder
解码器隐藏状态初始化,在$t=0$时刻
其中,$\mathbf{V}\in\mathbb{R}^{1000\times 1000}$为权值矩阵。
在$t$时刻第$j$个隐藏单元
其中,
其中,$\mathbf{W}^{\prime},\mathbf{W}_z^{\prime},\mathbf{W}_r^{\prime}\in\mathbb{R}^{1000\times 500}$和$\mathbf{U}^{\prime},\mathbf{U}_z^{\prime},\mathbf{U}_r^{\prime}\in\mathbb{R}^{1000\times 1000}$以及$\mathbf{C}^{\prime},\mathbf{C}_z^{\prime},\mathbf{C}_r^{\prime}\in\mathbb{R}^{1000\times 1000}$为权值矩阵。
目标文本单词的词嵌入表示:$e\left(\mathbf{y}_i\right)\in\mathbb{R}^{500}$,且在$t=0$时刻$e\left(\mathbf{y}_0\right)=\mathbf{0}$。
在每个时刻$t$,解码器计算生成第$j$个单词的概率
其中,最大输出单元(maxout unit)
且
$\mathbf{O}_h,\mathbf{O}_c\in\mathbb{R}^{500\times 1000}$和$\mathbf{O}_y\in\mathbb{R}^{500\times 500}$以及$\mathbf{G}=\left[\mathbf{g}_1,\cdots,\mathbf{g}_K\right]\in\mathbb{R}^{K\times 1000}$为权值矩阵。
Deep Learning nlp seq2seq encoder-decoder
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!