word2vec
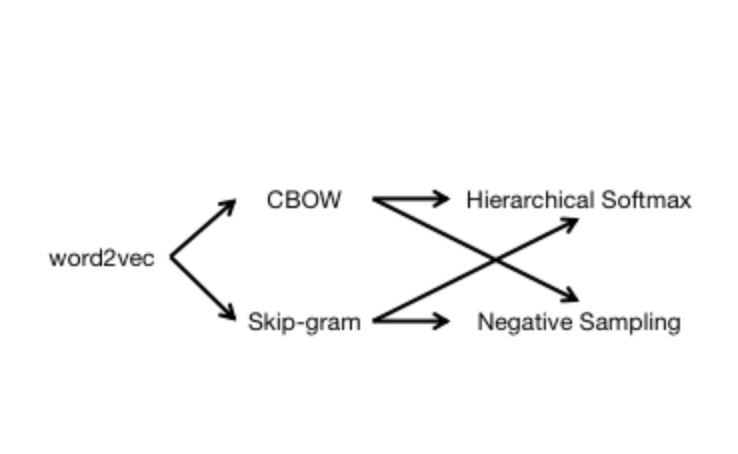
1 连续词袋模型(CBOW)与跳字模型(Skip-gram)
单词$w$;
词典$\mathcal{D}=\{w_1,w_2,\dots,w_N\}$,由单词组成的集合;
语料库$\mathcal{C}$,由单词组成的文本序列;
单词$w_t$的上下文是语料库中由单词$w_t$的前$c$个单词和后$c$个单词组成的文本序列,$w_t$称为中心词。

连续词袋模型(CBOW, Continuous Bag-of-Words Model)假设中心词由该词在文本序列中的上下文来生成。
跳字模型(Skip-gram)假设中心词生成该词在文本序列中的上下文。
2 基于层序softmax(Hierarchical softmax)方法的连续词袋模型训练
基于层序softmax方法的连续词袋模型网络结构:
输入层:$\mathbf{v}\left(Context\left(w\right)_1\right),\mathbf{v}\left(Context\left(w\right)_2\right),\cdots,\mathbf{v}\left(Context\left(w\right)_{2c}\right)\in\mathbb{R}^m$,其中$\mathbf{v}\left(\cdot\right)$为单词的向量化表示;
投影层:$\mathbf{x}_w=\sum_{i=1}^{2c}\mathbf{v}\left(Context\left(w\right)_i\right)\in\mathbb{R}^m$;
输出层:$T_{Huff}\left(\mathbf{x}_w\right)=s_{q\left(\mathbf{x}_w\right)},s\in\mathbb{R}^N,q:\mathbb{R}^m\to\{1,2,\cdots,N\}$,其中$N$为哈夫曼树叶子结点个数。

记为从根节点出发到达$w$对应的叶子结点的路径。其中,$l^w$为路径长度,即路径中结点数目;$p_i^w$为路径中的结点,$p_1^w$为根结点,$p_{l^w}^w$为$w$对应的叶子结点。
记
为$w$的Huffman编码。其中,$d_i^w\in\{0,1\}$为路径$p^w$中第$i$个结点对应的编码(根结点不对应编码)。
记
为路径$p^w$中非叶子结点对应的参数向量。其中,$\theta_i^w\in\mathbb{R}^m$为路径$p^w$中第$i$个非叶子结点对应的参数向量。
条件概率
其中
或者
似然函数
对数似然函数
对数似然函数$\mathcal{L}$关于$\theta_{j-1}^w$的偏导
$\theta_{j-1}^w$的更新
其中,$\eta$为学习率。
对数似然函数$\mathcal{L}$关于$\mathbf{x}_w$的偏导
$\mathbf{v}\left(\tilde{w}\right)$的更新
其中,$\tilde{w}\in Context\left(w\right)$。
3 基于层序softmax(Hierarchical softmax)方法的跳字模型训练
基于层序softmax方法的跳字模型网络结构:
输入层:$\mathbf{v}\left(w\right)\in\mathbb{R}^m$
输出层:$T_{Huff}\left(\mathbf{v}_w\right)=s_{q\left(\mathbf{v}_w\right)},s\in\mathbb{R}^N,q:\mathbb{R}^m\to\{1,2,\cdots,N\}$
条件概率
其中
且
似然函数
对数似然函数
对数似然函数$\mathcal{L}$关于$\theta_{j-1}^u$的偏导
$\theta_{j-1}^u$的更新
其中,$\eta$为学习率。
对数似然函数$\mathcal{L}$关于$\mathbf{v}\left(w\right)$的偏导
$\mathbf{v}\left(w\right)$的跟新
4 基于负采样(Negative Sampling)方法的连续词袋模型训练
设$Context\left(w\right)$的负样本子集为
对于$\forall\tilde{w}\in\mathcal{D}$,定义
表示词$\tilde{w}$的标签,正样本标签为$1$,负样本标签为$0$。
关于字典$\mathcal{D}$的子集$\{w\}\bigcup NEG\left(w\right)$的似然函数
其中
或者
$\mathbf{x}_w$为$Context\left(w\right)$词向量之和,$\theta^u\in\mathbb{R}^m$为模型参数。
关于语料库$\mathcal{C}$的对数似然函数
对数似然函数$\mathcal{L}$关于$\theta^u$的偏导
$\theta^u$的更新
对数似然函数$\mathcal{L}$关于$\mathbf{x}_w$的偏导
$\mathbf{v}\left(\tilde{w}\right)$的更新
其中,$\tilde{w}\in Context\left(w\right)$。
5 基于负采样(Negative Sampling)方法的跳字模型训练
关于字典$\mathcal{D}$的子集$\{w\}\bigcup NEG^{\tilde{w}}\left(w\right)$的似然函数
其中
或者
$NEG^{\tilde{w}}\left(w\right)$为处理词$\tilde{w}$时生成的负样本子集。
关于语料库$\mathcal{C}$的对数似然函数
对数似然函数$\mathcal{L}$关于$\theta^u$的偏导
$\theta^u$的更新
对数似然函数$\mathcal{L}$关于$\mathbf{v}\left(\tilde{w}\right)$的偏导
$\mathbf{v}\left(\tilde{w}\right)$的更新
负采样算法

设词典$\mathcal{D}$中词$w_i$对应线段$l\left(w_i\right)$,长度为
其中,$counter\left(\cdot\right)$为词在语料$\mathcal{C}$中的出现次数。可将线段$l\left(w_1\right)\cdots l\left(w_N\right)$拼接为长度为$1$的单位线段。
记
则以$\{l_j\}_{j=0}^N$为剖分点可得到区间$\left[0,1\right]$上的一个非等距剖分
在区间$\left[0,1\right]$上以剖分点$\left\{m_j\right\}_{j=0}^M$做等距剖分,其中$M\gg N$。
将等距剖分的内部点$\left\{m_j\right\}_{j=1}^{M-1}$投影到非等距剖分。则可建立$\left\{m_j\right\}_{j=1}^{M-1}$与区间$\left\{I_j\right\}_{j=1}^N$的映射,进一步建立与词$\left\{w_j\right\}_{j=1}^M$之间的映射