Seq2Seq with Attention
1 序列到序列任务中的注意力机制
Seq2Seq with Attention网络架构
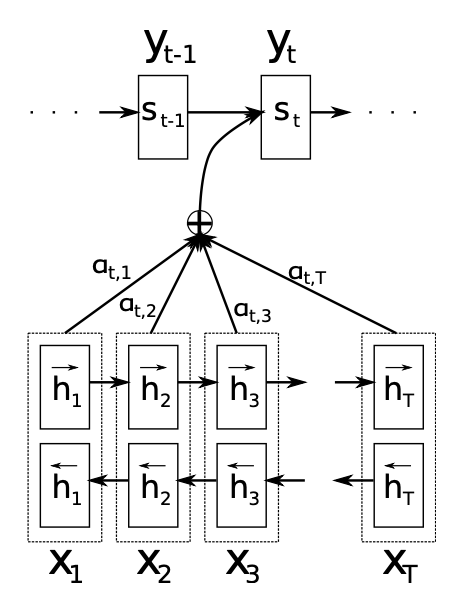
seq2seq with Attention神经网络架构中,编码器采用双向循环神经网络学习将输入序列$\mathbf{x}$编码成每个时刻的上下文向量(注意力分布)$c_i$,解码器学习将上下文向量$c_i$解码为输出序列$\mathbf{y}$。
源文本序列:$\mathbf{x}=\left(x_1,\cdots,x_{T_x}\right)$,其中$x_i\in\mathbb{R}^{K_x}$为one-of-K编码 ,$K_x$为源语言词表长度,$T_x$为源语料长度。
目标文本序列:$\mathbf{y}=\left(y_1,\cdots,y_{T_y}\right)$,其中$y_i\in\mathbb{R}^{K_y}$为one-of-K编码,$K_y$为目标语言词表长度,$T_y$为目标语料长度。
Seq2Seq with Attention编码器Encoder原理
编码器Encoder采用双向循环神经网络,前向状态计算
其中,
$\overline{E}\in\mathbb{R}^{m\times K_x}$为词嵌入矩阵,$m$为词嵌入维度。$\overrightarrow{W},\overrightarrow{W}_z,\overrightarrow{W}_r\in\mathbb{R}^{n\times m}$和$\overrightarrow{U},\overrightarrow{U}_z,\overrightarrow{U}_r\in\mathbb{R}^{n\times n}$为权值矩阵,$n$为隐藏单元数。$\sigma\left(\cdot\right)$通常为sigmoid函数。
后向状态$\left(\overleftarrow{h}_1,\cdots,\overleftarrow{h}_{T_x}\right)$计算相同。与权值矩阵不同,我们在前向和后向RNN网络中共享词嵌入矩阵$\overline{E}$。
将前向和后向状态关联起来得到注释$\left(h_1,h_2,\cdots,h_{T_x}\right)$,
其中,
Seq2Seq with Attention解码器Decoder原理
解码器Decoder隐层转态$s_i$由解码器注释$h_i$计算的注意力分布$c_i$得到
其中,
$E\in\mathbb{R}^{m\times K_y}$为目标语言的词嵌入矩阵,$m$为词嵌入维度。$W,W_z,W_r\in\mathbb{R}^{n\times m}$和$U,U_z,U_r\in\mathbb{R}^{n\times n}$以及
$C,C_z,C_r\in\mathbb{R}^{n\times 2n}$为权值矩阵,$n$为隐藏单元数。隐层初始状态$s_0=\tanh\left(W_s\overleftarrow{h}_1\right)$,其中$W_s\in\mathbb{R}^{n\times n}$。
每个时刻的上下文向量(注意力分布)$c_i$的计算
其中,
$h_j$为源文本序列第$j$个注释。$v_a\in\mathbb{R}^{n^{‘}},W_a\in\mathbb{R}^{n^{‘}\times n},U_a\in\mathbb{R}^{n^{‘}\times 2n}$为权值矩阵。
使用解码器状态$s_{i-1}$,上下文$c_i$和上时刻生成单词$y_{i-1}$定义目标单词$y_i$的概率
其中,
$\tilde{t}_{i,k}$是向量$\tilde{t}_i$的第$k$个元素,
$W_o\in\mathbb{R}^{K_y\times l},U_o\in\mathbb{R}^{2l\times n},C_o\in\mathbb{R}^{2l\times 2n}$是权值矩阵。
2 注意力机制
柔性注意力机制(Soft Attention)
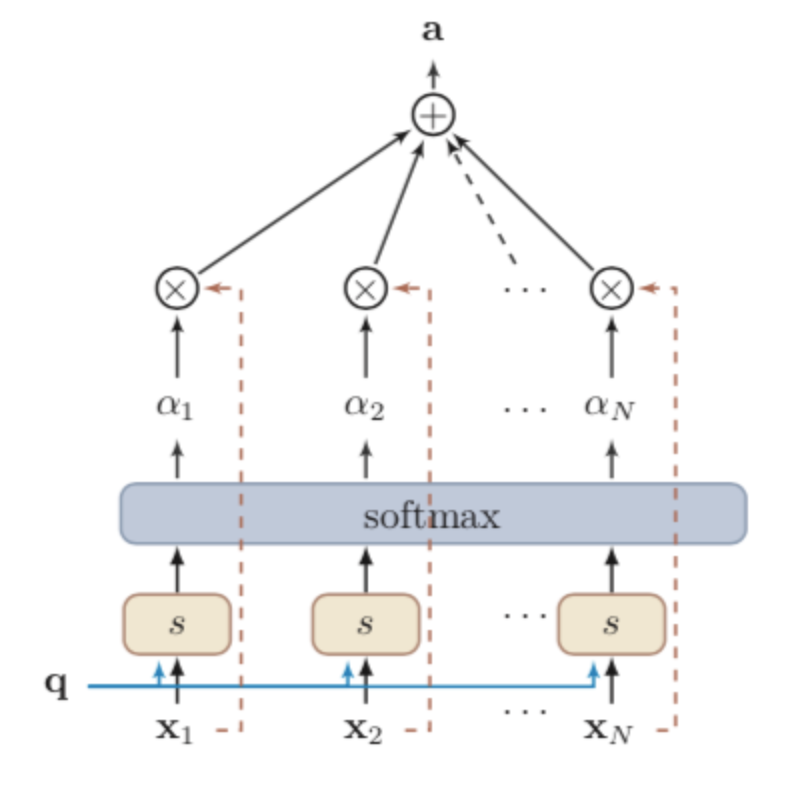
输入信息$X=\left[\mathbf{x}_1,\cdots,\mathbf{x}_N\right]$
注意力机制的计算:
- 在输入信息上计计算注意力分布;
- 根据注意力分布计算输入信息的加权平均。
注意力分布
给定一个和任务相关的查询向量$\mathbf{q}$,用注意力变量$z\in\left[1,N\right]$表示被选择信息的索引位置,即$z=i$表示选择了第$i$个输入信息。其中,查询向量$\mathbf{q}$可以是动态生成的,也可以是可学习的参数。
软性注意力的注意力分布
在给定输入信息$X$和查询变量$\mathbf{q}$下,选择第$i$个输入信息的概率
其中,$\alpha_i$称为注意力分布,$s\left(\mathbf{x}_i,\mathbf{q}\right)$称为注意力打分函数。
注意力打分函数
- 加性模型 $s\left(\mathbf{x}_i,\mathbf{q}\right)=\mathbf{v}^\top\tanh\left(W\mathbf{x}_i+U\mathbf{q}\right)$
- 点积模型 $s\left(\mathbf{x}_i,\mathbf{q}\right)=\mathbf{x}_i^\top\mathbf{q}$
- 缩放点积模型 $s\left(\mathbf{x}_i,\mathbf{q}\right)=\frac{\mathbf{x}_i^\top\mathbf{q}}{\sqrt{d}}$
- 双线性模型 $s\left(\mathbf{x}_i,\mathbf{q}\right)=\mathbf{x}_i^\top W\mathbf{q}$
其中,$W,U,\mathbf{v}$为可学习的网络参数,$d$为输入信息的维度。
加性模型和点积模型的复杂度近似,但点积模型可利用矩阵乘积,计算效率跟高。当输入信息的维度$d$比较高,点积模型值方差较大,导致softmax函数的梯度较小,缩放点积模型可以解决。双线性模型是泛化的点积模型。若假设$W=U^\top V$,则$s\left(\mathbf{x}_i,\mathbf{q}\right)=\mathbf{x}_i^\top U^\top V\mathbf{q}=\left(U\mathbf{x}_i\right)^\top\left(V\mathbf{q}\right)$,即分别对$\mathbf{x}_i$和$\mathbf{q}$进行线性变换后进行点积。相比点积模型,双线性模型在计算相似度是引入了非对称性。
注意力分布$\alpha_i$可解释为在给定相关查询$\mathbf{q}$时,第$i$个信息受关注的程度。
加权平均
注意力函数
键值对注意力机制(Key-Value Pair Attention Mechanism)
输入信息$\left(K,V\right)=\left[\left(\mathbf{k}_1,\mathbf{v}_1\right),\cdots,\left(\mathbf{k}_N,\mathbf{v}_N\right)\right]$,其中键用来计算注意力分布$\alpha_i$,值用来计算聚合信息。
给定任务相关查询向量$\mathbf{q}$时,注意力分布
注意力函数
其中,$s\left(\mathbf{k}_i,\mathbf{q}\right)$为打分函数。当$K=V$时,键值对注意力机制等价为柔性注意力机制。

多头注意力机制(Multi-Head Attention Mechanism)
多个查询$Q=\left[\mathbf{q}_1,\cdots,\mathbf{q}_M\right]$平行的计算从输入信息中选取多个信息。每个注意力关注输入信息的不同部分。
其中,$\oplus$为向量拼接。
自注意力模型(Self-Attention Model)
输入序列$X=\left[\mathbf{x}_1,\cdots,\mathbf{x}_N\right]\in\mathbb{R}^{d_1\times N}$
输出序列$H=\left[\mathbf{h}_1,\cdots,\mathbf{h}_N\right]\in\mathbb{R}^{d_2\times N}$
通过线性变换得到向量序列:
其中,$Q$为查询向量序列,$K$为键向量序列,$V$为值向量序列,$W_Q,W_K,W_V$分别为可学习参数矩阵。
预测输出向量
其中,$i,j\in\left[1,N\right]$为输出和输入向量序列的位置,连接权重$\alpha_{ij}$由注意力机制动态生成。
若使用缩放点积模型作为打分函数,则输出向量序列
其中,softmax为按列归一化的函数。
自注意力模型计算的权重$\alpha_{ij}$只依赖$\mathbf{q}_i$和$\mathbf{k}_j$的相关性,而忽略了输入信息的位置信息。因此自注意力模型一般需要加入位置编码信息来进行修正。
Deep Learning nlp seq2seq attention soft attention key-value pair attention multi-head attention
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!